
Loguru —- python日志
- 技术
- 2024-05-14
- 889热度
- 0评论
为什么要使用 Python 日志
在进入公司实习接触到一个比较大型的项目之后,才发现日志是多么有用的东西。日志不仅可以帮助开发者快速定位问题,还能记录程序的运行状态,方便后续的维护和优化。对于 Python,虽然 Python 自带了强大的日志库 `logging`,但它的配置相对较为繁琐。而 `loguru` 作为一个第三方库,却可以将这个过程变得十分简单,同时输出十分优雅。
在实际开发中,日志的作用主要体现在以下几个方面:
- 问题排查:通过日志可以快速定位程序中出现的问题,尤其是生产环境中的问题。
- 运行监控:日志可以帮助开发者了解程序的运行状态,及时发现潜在的性能问题。
- 调试辅助:在开发过程中,日志可以替代 `print()`,提供更清晰、更结构化的调试信息。
- 历史记录:日志文件可以保留程序的运行历史,方便后续的分析和追溯。
快速了解 Loguru
关于编程的问题,当然是官方文档先行。我们来快速查看一个例子:
from loguru import logger
logger.add(".\\loguru.log", format="{time} {name}:{line} {level} {message}", filter="", encoding="utf-8")
@logger.catch
def divide_by_0(x:int):
logger.info("=============divide by 0==============")
return x/0
@logger.catch
def access_nonexistent_dict_key():
logger.info("=============access_nonexistent_dict_key==============")
my_dict = {"name": "Alice", "age": 30}
return my_dict["address"]
if __name__ =="__main__":
divide_by_0(6)
access_nonexistent_dict_key()
在这个例子里,Loguru 体现了它的三个特性:
logger 配置
Logger 只需要在导入的时候进行一次配置,无论多复杂的项目,也只需要配置一次即可。在上面的示例中,我们主要设置了其输出格式和编码,同时将日志保留到项目目录的 `log` 文件夹中。当然,在实际生产项目中,我们可以结合 `os.getlogin()` 或其他路径来使用。
主要参数
以下是一些常用的 `logger.add()` 参数及其描述:
- sink:日志输出的目标,可以是文件路径、流对象(如 `sys.stdout`)、函数、类实例等。示例:`logger.add("file.log")`,`logger.add(sys.stdout)`。
- level:设置日志记录的级别,只有级别高于或等于该设置的日志信息才会被记录。常见级别有 "DEBUG"、"INFO"、"WARNING"、"ERROR"、"CRITICAL"。示例:`logger.add("file.log", level="INFO")`。
- format:定义日志记录的格式。可以使用预定义的占位符来定制日志格式,如 {time}、{level}、{message} 等。示例:`logger.add("file.log", format="{time} {level} {message}")`。
- filter:指定一个过滤器函数或一个字符串,用于过滤日志记录。只有满足过滤器条件的日志才会被记录。示例:`logger.add("file.log", filter=lambda record: record["level"].name == "INFO")`。
- rotation:设置日志文件的轮换策略,可以按时间、文件大小或自定义逻辑进行轮换。示例:`logger.add("file.log", rotation="500 MB")`,`logger.add("file.log", rotation="00:00")`(每天午夜轮换)。
- retention:设置日志文件的保留策略,指定旧日志文件的保留时长或数量。示例:`logger.add("file.log", retention="10 days")`。
- compression:指定日志文件轮换后的压缩格式,可以是 "zip"、"tar" 等。示例:`logger.add("file.log", compression="zip")`。
- encoding:指定日志文件的编码格式。示例:`logger.add("file.log", encoding="utf-8")`。
- enqueue:如果设置为 True,日志记录将通过线程安全的队列异步处理,以避免多线程环境下的并发问题。示例:`logger.add("file.log", enqueue=True)`。
- backtrace:如果设置为 True,当发生异常时,日志记录将包含完整的回溯信息,包括导致错误的上下文。示例:`logger.add("file.log", backtrace=True)`。
- diagnose:如果设置为 True,当发生异常时,日志记录将包含详细的诊断信息,有助于调试。示例:`logger.add("file.log", diagnose=True)`。
装饰器用于收集错误
关于装饰器是什么可以参考我的文章。使用装饰器 `@logger.catch`,可以给函数套上一层类似 `try-except` 的错误收集机制,然后可以优雅而清晰地获得错误信息:
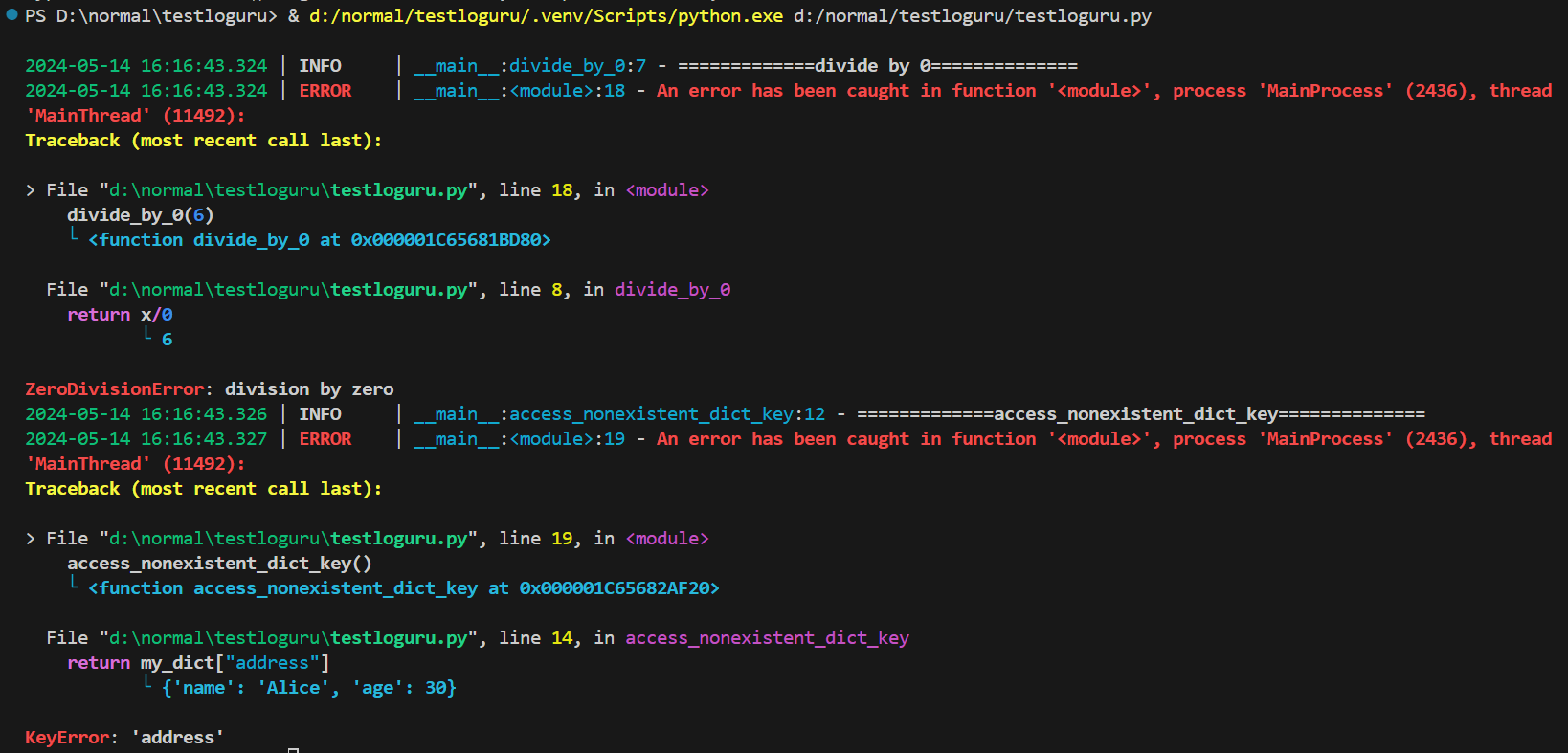
Loguru 会自动将不同的部分标识出来,出错的部分会将其值表示出来。
通过不同日志等级输出
调试程序不会还在使用 `print()` 吧?不仅格式杂乱,而且后期还不方便删除。试试 `logger.debug(msg)`,将调试信息非常方便地输出出来,后期在配置中屏蔽 `DEBUG` 级别的日志即可。
以下是一个完整的示例,展示如何使用不同日志等级输出:
from loguru import logger
# 配置日志输出到文件,设置日志级别为DEBUG
logger.add("debug.log", level="DEBUG", format="{time} {level} {message}", encoding="utf-8")
# 输出不同级别的日志
logger.debug("这是一个调试信息")
logger.info("这是一个普通信息")
logger.warning("这是一个警告信息")
logger.error("这是一个错误信息")
logger.critical("这是一个严重错误信息")
# 使用装饰器捕获函数中的异常
@logger.catch
def divide_by_zero():
return 1 / 0
divide_by_zero()
在这个示例中:
- 我们配置了日志输出到文件 `debug.log`,并设置了日志级别为 `DEBUG`。
- 通过 `logger.debug()`、`logger.info()`、`logger.warning()`、`logger.error()` 和 `logger.critical()` 输出不同级别的日志信息。
- 使用 `@logger.catch` 装饰器捕获函数中的异常,并自动记录异常信息。
Loguru 的强大之处在于它简化了日志配置的复杂性,同时提供了丰富的功能,使得日志记录变得简单而高效。无论是开发阶段的调试,还是生产环境中的问题排查,Loguru 都是一个非常实用的工具。
